
Full code available on Github
Today we’re going to walk through implementing your own local LLM RAG app using Ollama and open source model Llama3. Let’s get into it.
When LLMs Fall Short
So you have heard about these new tools called Large Language Models (LLMs) and you want in, you head over to ChatGPT, type in your question and get a good response, success. You decide to step it up and type in something more specific and current related to your business. The result is less than ideal, you are met with a message that states the model was not training on data after X date or worse, the model has hallucinated and has given you a completely wrong answer. So what do you do now, give up?
The problem I’ve laid out here is a common one with LLMs. The model training is a costly and intensive process which only has access to publicly available information. For practical, business use cases we need responses to be current and based on internal knowledge. There are two primary methods to achieve this; fine tuning & retrieval augmented generation (RAG).
Fine Tuning – Process where a pre-trained model, like GPT-4o, is further trained on a specific dataset to adapt it to a particular task or domain. This involves taking the trained model and tweaking its parameters so it performs better on the desired task, like answering questions about medical information or reviewing quarterly reports. Essentially, it’s like teaching a generally smart assistant to become an expert in a specific area by giving it additional, targeted training.
Retrieval Augmented Generation (RAG) – Approach where the model retrieves relevant information from external sources to help generate more accurate and informative responses. Instead of relying solely on its pre-trained knowledge, the model looks up additional data from a database or search engine, combines this retrieved information with its own understanding, and then produces a response. This approach helps the model provide more precise and up-to-date answers by leveraging external resources during the generation process.
Proprietary Data Dilemma & Open Source
You still have one more problem to overcome, LLMs are brand new and as such many corporation’s legal & security departments are still trying to figure out processes and policies to help safeguard their company against theft and exposure of their data. This is a perfectly legitimate expectation to have. So where does that leave us? We want to use LLMs to talk with our data and offer all the advantages they promise. Do you have to wait? Not at all, open source has your back.
Ever since Meta released the first Llama model we have seen an explosion within the open source community, chasing the larger tech companies to try take a slice of the pie. This race has opened up opportunities to experiment with these models completely locally, reducing the red tape while allowing you to operate within your companies existing policies.
I may hear you say, “but dealing with Open Source is really technical”, thankfully, the community has been hard at work and with services like Ollama & HuggingFace, working with Open Source models couldn’t be easier. So if it wasn’t obvious, we’re going to walk through building a RAG application with an open source LLM as the brains. Before we get to it, let’s look at the workflow we will follow.
Retrieval Augmented Generation (RAG)
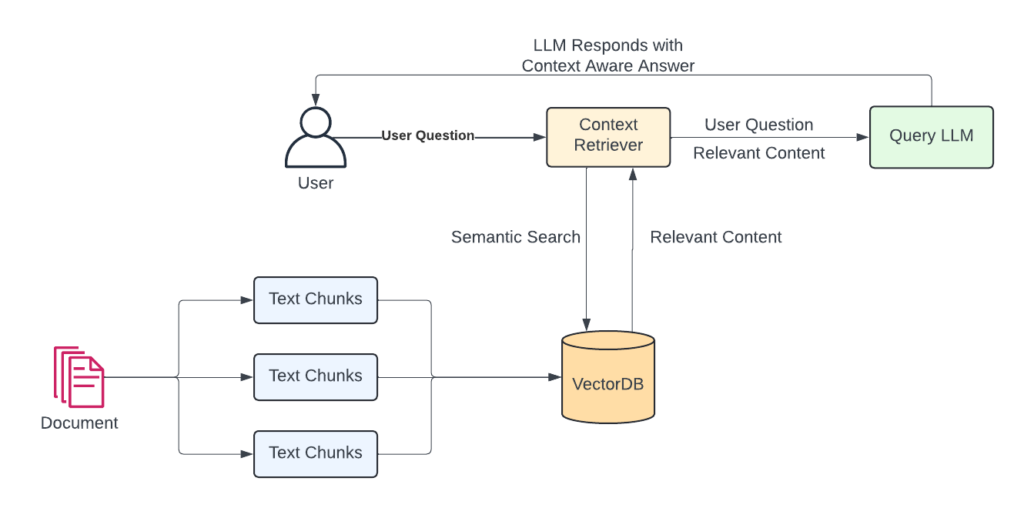
When dealing with RAG it is important to understand the core workflows. Using the diagram here, your typical LLM interaction is the top part, user asks question, LLM responds with answer. For RAG we have some extra steps.
- Text Chunking – First we must chop up our content into text chunks. All LLMs have a context window, this is the maximum number of tokens that we can send at one time. The key here is to get relevant content. By chunking the content we can better retrieve only what is relevant and therefore stay within the context window limitation.
- Convert to Vectors & Store in VectorDB – We do this for two reasons. First, LLMs understand the world in vectors, so we are getting the text into a form which is more easily understood by them. Second is that text converted to vectors allows us to perform a Semantic Search for relevant data chunks.
- Semantic Search – Put simply, this allows us to use these numerical representations to search for similar content. Returning only the relevant content is critical to maintaining a small context window while grant the LLM access to new information. RAG applications tend to use Approximate Nearest Neighbours (ANN) as a more efficient clustering algorithm to find similar content to our query.
- Combined Prompt – With RAG, we combine the question with content that is relevant to that questions. This is no different to adding context to your prompt before asking an LLM. Something like “Today is my birthday, I am 30 years old” followed by “When is my birthday”. RAG does this but with more sophistication.
Bringing it all together, if you had documentation on quarterly performance and product descriptions, asking the LLM for last quarters numbers would fetch the vectorized text chunks for quarterly performance, merge that with your query, send to the LLM and provide a response based on your content, easy right!!!
Show Me the Code
Let’s nail this down with an example, to keep it simple our example will use a PDF with some content in it that couldn’t possibly be known to the LLM based on it’s training date. I like to grab the content of a news article from today, just to prove that the knowledge is current. For this example we’ll use the following components.
Components
- Langchain – A framework for building LLM powered apps. Balances core with community based tools to make the whole process easier and faster to go from idea to working app. The core premise behind langchain is the concept of chains. In this, Chains, agents, and retrieval strategies are brought together to make up an application’s cognitive architecture.
- ChromaDB – An open source, lightweight vector database that is excellent for small scale services and use cases. VectorDBs form an integral part of any LLM based app as they store text data in a vector format, which is what AI and ML models natively use. Think of a vector database as the memory of your AI.
- Ollama – Tool that allows you to run open source models locally, easily. This eliminates all of the setup and integration elements required to normally get these models running within an application. For our example here, we will be leveraging the latest Llama3 model from Meta which was available via Ollama on the day of release.
- Streamlit – Open source framework for rapidly & easily building web interfaces on top of machine learning and data science applications. Streamlit turns data scripts into shareable web apps in minutes. All in pure Python. No front‑end experience required. Excellent framework for anyone who wants a professional looking UI in a fraction of the time.
With the components laid out, let’s get to building – starting with initializing our project first.
Initialize the Project
I like to use Poetry for dependency management, you can find a great tutorial on getting started on their website. Regardless of what dependency management system you use the following dependencies will need to be installed.
poetry add langchain chromadb streamlit
Create UI for Document Upload
Since we will be working with documents, we’ll start by creating a simple interface within Streamlit.
Create a file called app.py and drop the following code into it. This will use Streamlit to create a simple UI that allows us to upload a PDF.
An interesting element which we will use later is the session state. In this we will store the chat history so we have access to it across page refreshes. Streamlit operates through regular refreshes so session state is vital to maintaining state through these refresh action.
def init_ui():
"""
init_ui Initializes the UI
"""
st.set_page_config(page_title="Langchain RAG Bot", layout="wide")
st.title("Langchain RAG Bot")
# Initialise session state
if "chat_history" not in st.session_state:
st.session_state.chat_history = [
AIMessage(content="Hello, I'm here to help. Ask me anything!")
]
with st.sidebar:
st.header("Document Capture")
st.write("Please select a single document to use as context")
st.markdown("**Please fill the below form :**")
with st.form(key="Form", clear_on_submit = True):
uploaded_file = st.file_uploader("Upload", type=["pdf"], key="pdf_upload")
submit = st.form_submit_button(label="Upload")
if submit:
persist_file(uploaded_file)
Ollama
Before we move into creating the vector store you need to ensure you have Ollama running locally. This is required to create the correctly formatted Embeddings. Go to the Ollama Download page and follow the instructions for your system. They have a Windows version in preview, if that doesn’t work for you check out my article on getting this to work using Windows Subsystem for Linux (WSL).
Initialize the Vector Store
Now that we have a way to upload our context document PDF, let’s work on converting that content to a vector and storing it in our DB. To do this we will do the following:
- Use Langchain’s RecursiveCharacterTextSplitter to split the content into chunks
- From that list of document chunks, initialise the ChromaDB instance. We must choose what format of embeddings to use. Since we are using Ollama we’ll choose the OllamaEmbeddings object. If you were using OpenAI you would use OpenAIEmbeddings
- When complete we will have a functioning vector store with our context converted to embeddings that can be used in the next stage, creating the retrieval chain.
In the same app.py add the following function
def init_vector_store():
"""
Initializes and returns ChromaDB vector store from document chunks
Returns:
ChromaDB: Initialized vector store
"""
# Get the first file - in reality this would be more robust
files = [f for f in DATA_DIR.iterdir() if f.is_file]
if not files:
st.error("No files uploaded")
return None
# Get the path to the first file in the directory
first_file = files[0].resolve()
# Use the PDF loader in Langchain to fetch the document text
loader = PyPDFLoader(first_file)
document = loader.load_and_split()
# Now we initialise the text splitter we will use on the document
text_splitter = RecursiveCharacterTextSplitter()
document_chunks = text_splitter.split_documents(document)
# Lastly, we initialise the vector store using the split document
vector_store = Chroma.from_documents(
documents=document_chunks,
embedding=OllamaEmbeddings(),
persist_directory=str(DB_DIR),
collection_name="pdf_v_db" # Important if you want to reference the DB later
)
return vector_store
Create the Retriever Chain
Now that we have our context stored in ChromaDB we can begin building the retriever chain. The process is straightforward and goes like this:
- We want to stay within context window limits for our LLM. To achieve this we perform a semantic search against content in ChromaDB to fetch ONLY related content
- In this case, the semantic search is going to perform an Approximate Nearest Neighbour search to find the content which closely matches the users query
- We then merge the related context with the users original question. This allows us to supply the context along with the question, allowing the LLM to have unknown information to help answer the question
- Send the context aware question to the LLM
def get_related_context(vector_store: Chroma) -> RetrieverOutputLike:
"""
Will retrieve the relevant context based on the user's query
using Approximate Nearest Neighbor search (ANN)
Args:
vector_store (Chroma): The initialized vector store with context
Returns:
RetrieverOutputLike: The chain component to be used with the LLM
"""
# Specify the model to use
llm = Ollama(model="llama3")
# Here we are using the vector store as the source
retriever = vector_store.as_retriever()
# Create a prompt that will be used to query the vector store for related content
prompt = ChatPromptTemplate.from_messages([
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}"),
("user", "Given the above conversation, generate a search query to look up to get information relevant to the conversation")
])
# Create the chain element which will fetch the relevant content from ChromaDB
chain_element = create_history_aware_retriever(llm, retriever, prompt)
return chain_element
def get_context_aware_prompt(context_chain: RetrieverOutputLike) -> Runnable:
"""
Combined the chain element to fetch content with one that then creates the
prompt used to interact with the LLM
Args:
context_chain (RetrieverOutputLike): The retriever chain that can
fetch related content from ChromaDB
Returns:
Runnable: The full runnable chain that can be executed
"""
# Specify the model to use
llm = Ollama(model="llama3")
# A standard prompt template which combined chat history with user query
# NOTE: You MUST pass the context into the system message
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful assistant that can answer the users questions. Use provided context to answer the question as accurately as possible:\n\n{context}"),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{input}")
])
# This method creates a chain for passing documents to a LLM
docs_chain = create_stuff_documents_chain(llm, prompt)
# Now we merge the context chain & docs chain to form the full prompt
rag_chain = create_retrieval_chain(context_chain, docs_chain)
return rag_chain
Chat with Our RAG LLM
So we now have all the pieces required to run a RAG app based on a PDF we upload. There is just one piece missing, the actual chat interface that sends our question to the LLM. For this you can use the built in chat interface with Streamlit. This is a very fast way to get working with an LLM within your own application.
def get_response(user_query: str) -> str:
"""
Will use the query to fetch context & form a query to send to an LLM.
Responds with the result of the query
Args:
user_query (str): Query input but user
Returns:
str: Answer from the LLM
"""
context_chain = get_related_context(st.session_state.vector_store)
rag_chain = get_context_aware_prompt(context_chain)
res = rag_chain.invoke({
"chat_history": st.session_state.chat_history,
"input": user_query
})
return res["answer"]
def init_chat_interface():
"""
Initializes a chat interface which will leverage our rag chain & a local LLM
to answer questions about the context provided
"""
user_query = st.chat_input("Ask a question....")
if user_query is not None and user_query != "":
response = get_response(user_query)
# Add the current chat to the chat history
st.session_state.chat_history.append(HumanMessage(content=user_query))
st.session_state.chat_history.append(AIMessage(content=response))
# Print the chat history
for message in st.session_state.chat_history:
if isinstance(message, HumanMessage):
with st.chat_message("Human"):
st.write(message.content)
if isinstance(message, AIMessage):
with st.chat_message("AI"):
st.write(message.content)
The full code is available on Github.
Conclusion
Alright, so there you have it! I’ve walked through the nitty-gritty of leveraging Large Language Models (LLMs) for practical, business use cases. We started with understanding the limitations of LLMs and how fine-tuning and Retrieval Augmented Generation (RAG) can address these issues. Then, we dived into the nitty-gritty of building a RAG application using open-source tools.
It’s clear that while LLMs are powerful, they aren’t without their shortcomings, especially when it comes to accessing current or proprietary data. But fear not, because with a bit of ingenuity and the right tools, you can turn these challenges into opportunities. The combination of fine-tuning and RAG, supported by open-source models and frameworks like Langchain, ChromaDB, Ollama, and Streamlit, offers a robust solution to making LLMs work for you.
So go ahead, initialize that project, upload your document, and watch as your LLM transforms into a knowledgeable assistant, ready to provide up-to-date and relevant information at your command. Happy coding!
[…] those who follow me, you know I’m a big fan of local, open-source models (see Mastering RAG, Using Ollama with Open Source Model & Unleash Ollama on Windows). I experimented with a local […]