
Full code is available on Github
Unstructured Data to Query-able Graph
Today I am going to walk through an example of GraphRAG using Neo4j, LangChian & Streamlit to create a bot that can converse with your documents, converted into a knowledge graph. GraphRAG was proposed in February 2024 by a team at Microsoft Research. They have recently released an implementation based on that work which you should also check out. Before I dive in I want to do a quick overview of how knowledge graphs can work to produces a more comprehensive RAG implementation.
This article is the third in a connected series of articles exploring retrieval augmented generation techniques, the second focusing on knowledge graphs. In Mastering RAG I demonstrated how to build a simple RAG based app to incorporate knowledge from PDFs. This showed how we can extend the knowledge of LLMs beyond their original training data and defend against hallucinations. Later, in Building Knowledge Graphs, the focus was put on the concept of a knowledge graph and how we can use LLMs to overcome one of the challenges that arise from developing them.
RAG with Knowledge Graphs
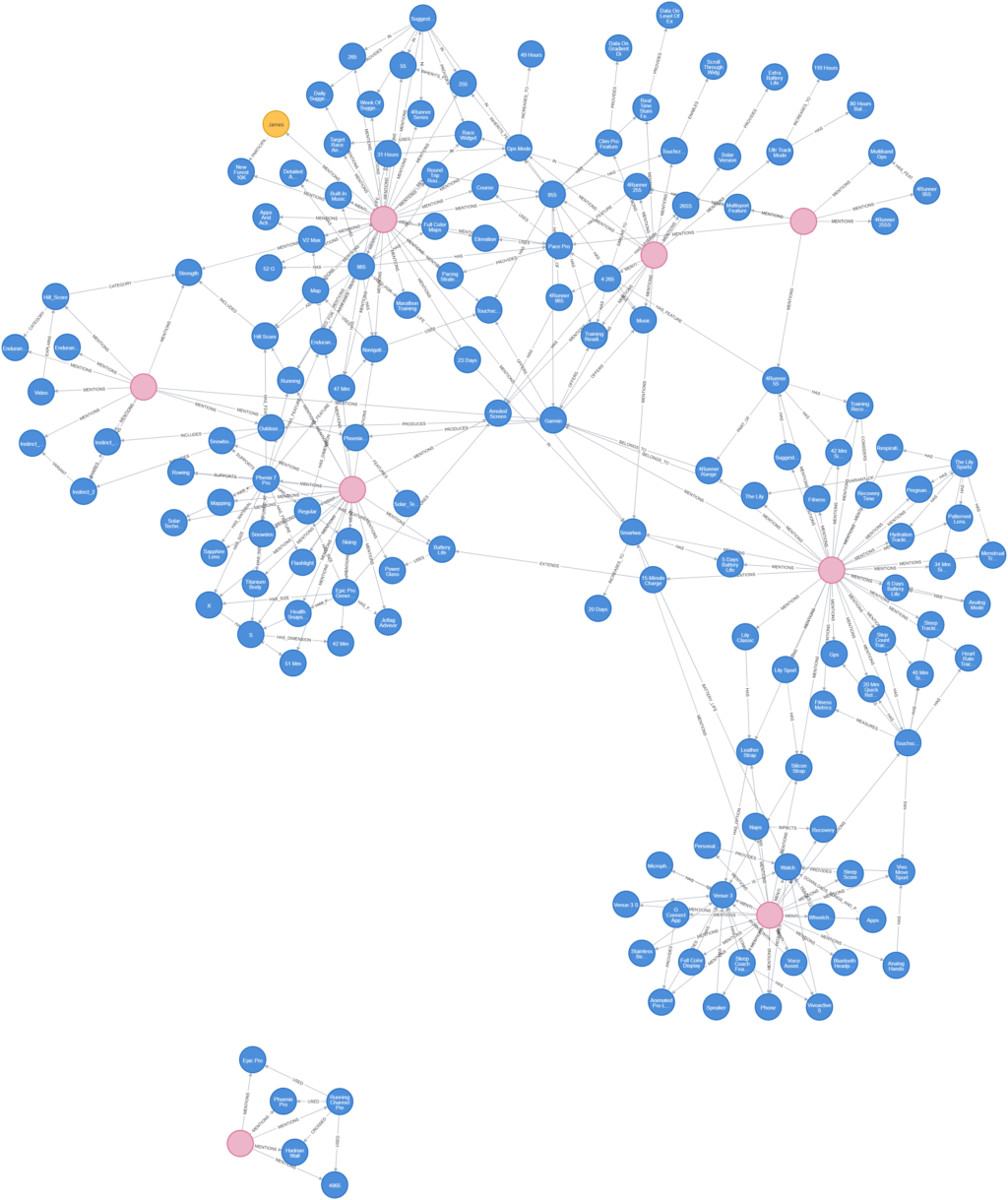
We already know that RAG is intended to assist LLMs to consume new knowledge beyond it’s original training data. This allows more recent or previously obscured information to be incorporated into the answers delivered to the user. This also has the benefit of reducing hallucinations, let’s call this basic RAG for now. While this delivers better results, and has it’s own optimisations, one challenge it has is in it’s ability to connect disparate knowledge separated by obscure relationships.
We know that information is often loosely related and context is not always cleanly connected. Knowledge graphs excel at both representing and querying these complex relationships. The term “multi-hop” is used to describe this concept, where an answer may lie across multiple relationship edges. With basic RAG implementations, the derived knowledge is quite often limited to exactly what is put in. For example, with our previous example of comparing Garmin running watches, it lacks the ability to understand that expert runners favour a more advanced set of training watches unless that fact is explicitly stated in the new data.
This is where knowledge graphs and RAG can come together. By leveraging the knowledge graphs ability to map and query multiple hops in a relationship we can construct more complex and rich answers. It does this by using both structured and unstructured data, retrieved from the new source documents, to provide a richer set of data points, related to the users query. Using the example above, not only could it return the fact that expert runners prefer a more advanced set of training watches, it can also return exactly what those watches are and what unique features they share. This is where the true power of RAG comes into play.
How It Works
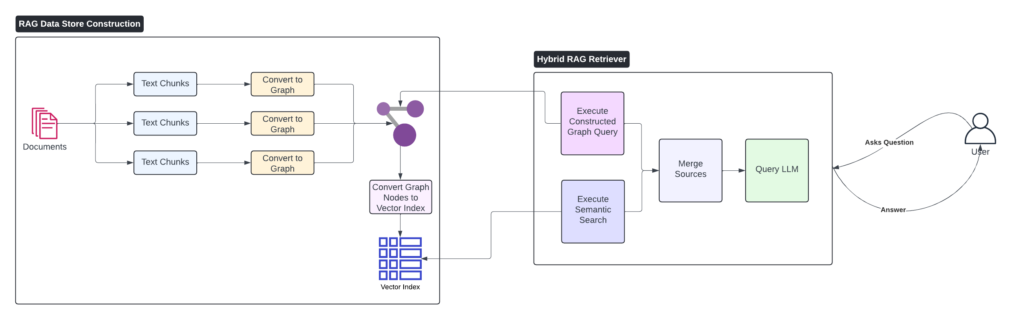
We’ll get into the details and the code in a few sections but I just want to take a moment to outline the high level architecture behind this implementation of a GraphRAG. The approach taken is to create a hybrid of both vectorized similarity search & graph queries to return both structured and unstructured data. In this way we can augment the benefits of basic RAG with the added context derived from querying the graph and its relationships.
Below is a simple outline of the process, broken out into two stages:
- RAG Data Store – This component is responsible for building up the data stores that will be used to retrieve context when a user poses a question. As with basic RAG, we chunk up the documents to make it compatible with an LLMs context window. Each chunk is converted into a graph document and the graph is iteratively built up from each successive document.
- Hybrid Retrieval – As this solution employs both a graph query & vector similarity search we leverage the constructed graph’s storage of the original document chunks and construct a vector index from them.
- Retriever – Here we accept a user question extract the entities from the question and then use these entities to conduct a vector search & construct a graph query. Combined, the resulting data is sent along side the original question to a LLM which returns a context aware answer.
Components
- LangChain – LangChain is an open-source framework that simplifies the process of building, deploying, and managing large language models (LLMs). It offers a robust infrastructure and a extensive library of integrations and functions that help prototype and develop LLM based apps quickly.
- Neo4j – Neo4j is a high-performance graph database management system. It leverages the Cypher query language for efficient querying and manipulation, making it ideal for applications requiring complex data relationships, such as recommendation engines, fraud detection, social networks, and IT infrastructure management.
- GPT-4o – The most recent model released by OpenAI at time of writing. Leveraging an impressive training set and building upon successive models, GPT-4o stands as the benchmark against which other models try to measure up. For this application we will use the integrations built into LangChain to interact with our model. You will need to bring your own API key.
- Streamlit – Streamlit is an open-source framework that enables developers to create and share beautiful, custom web applications for machine learning and data science projects with ease. By using simple Python scripts, Streamlit allows users to build interactive and visually appealing apps without requiring extensive knowledge of web development.
- youtube-transcript-api – Python library that retrieves transcripts or subtitles for YouTube videos, including automatically generated subtitles. It supports multiple languages and subtitle translation without requiring a headless browser. The API can be used programmatically or via a command-line interface, offering features such as batch fetching, formatting options, and proxy support.
- LLMGraphTransformer – NOTE: Still an experimental feature. The
LLMGraphTransformerfrom LangChain is a tool that converts documents into graph-based formats using a large language model (LLM). It allows users to specify node and relationship types, applying constraints and filtering as needed. The transformer can process documents asynchronously and supports structured outputs based on the provided schema and constraints, making it ideal for transforming text data into structured graph data for various applications.
Example Case – Garmin Watch Recommendations
Even though I already bought my new Garmin Forerunner 255 I’m going to continue on with it as the basis for our example. With a multitude of variations, features and price points it offers an excellent example to work from. As a sneak peak to where I’m ultimately going with this, it also is a great basis for an agent with specialist knowledge represented in a small graph – keep an eye out for that one.
I think that’s enough setup – let’s get into some code
Application Overview
The example application we’re working with has four main components:
- Neo4j hosted locally using Docker
- A graph builder that can extract unstructured text and convert it into a knowledge graph using AI
- A hybrid retriever that combines structured and unstructured text from the graph
- A Streamlit UI that allows the user to have a conversation with their graphed knowledge documents
Setup Neo4j Environment with Docker
Firstly I setup a local Neo4j instance running, using Docker for simplicity. First thing to do is download the APOC JAR and place into a $PWD/plugins directory. This can technically be anywhere you like, just ensure the following docker command knows where you dropped the JAR. APOC is a companion library for Neo4j that includes helpful functions that assist in it’s operation. It is required for this example.
Ensure you have Docker Desktop already installed and execute the following command
docker run `
-p 7474:7474 -p 7687:7687 `
-v ${PWD}/data:/data -v ${PWD}/plugins:/plugins `
--name neo4j-v5-apoc `
-e NEO4J_apoc_export_file_enabled=true `
-e NEO4J_apoc_import_file_enabled=true `
-e NEO4J_apoc_import_file_use_neo4j_config=true `
-e NEO4J_PLUGINS='["apoc"]' `
-e NEO4J_dbms_security_procedures_unrestricted="apoc.*" `
neo4j:5.20.0
The above is formatted for a Powershell environment, adjust accordingly for your system/terminal.
Building the Graph from Unstructured Data
To demonstrate combining multiple source types I’ve created three document extractors. One for YouTube, Wikipedia & plain text.
def extract_youtube_transcript(self, url) -> List:
"""
Uses the Langchain interface to extract YouTube transcript from
the specified URL. Under the hood this uses youtube-transcript-api
Args:
url (str): URL of the YouTube video to fetch transcript for
Returns:
List: Extracted transcript documents
"""
return YoutubeLoader.from_youtube_url(url).load()
def extract_wikipedia_content(self, search_query):
"""
Uses the search query and LangChain interface to extract
content from the results of a Wikipedia search
Args:
search_query (str): The query to search for Wikipedia content on
"""
raw_docs = WikipediaLoader(query=search_query).load()
self.chunk_and_graph(raw_docs)
def graph_text_content(self, path):
"""
Provided with a text document, will extract and chunk the text
before generating a graph
Args:
path (str): Text document path
"""
text_docs = TextLoader(path).load()
print(text_docs)
self.chunk_and_graph(text_docs)
With the content extracted you now need to chunk the text. There are a number of strategies emerging for efficiently chunking up documents for RAG implementation, in this case I stuck to a simple TokenTextSplitter.
def chunk_document_text(self, raw_docs):
"""
Accepts raw text context extracted from source and applies a chunking
algorithm to it.
Args:
raw_docs (str): The raw content extracted from the source
Returns:
List: List of document chunks
"""
text_splitter = TokenTextSplitter(chunk_size=512, chunk_overlap=24)
docs = text_splitter.split_documents(raw_docs[:3])
return docs
For each chunk we begin the process of converting it into a graph document and persist to the underlying Neo4j instance. This is where I leveraged the LLMGraphTransformer to convert the plain text chunks into graph nodes and edges.
def graph_document_text(self, text_chunks):
"""
Uses experimental LLMGraphTransformer to convert unstructured text into a knowledge graph
Args:
text_chunks (List): List of document chunks
"""
llm_transformer = LLMGraphTransformer(llm=self.llm)
graph_docs = llm_transformer.convert_to_graph_documents(text_chunks)
self.graph.add_graph_documents(
graph_docs,
baseEntityLabel=True,
include_source=True
)
This process repeats for all chunks across all source documents until complete. An interesting point to note is include_source=True. This will show the source documents as part of the graph. This is useful for the unstructured semantic search step later.
Finally, I create an index across the graph to assist with efficient searching. This step must be complete after all new content is added to the graph.
def index_graph(self):
"""
Creates an index on the populated graph tp assist with efficient searches
"""
self.graph.query(
"CREATE FULLTEXT INDEX entity IF NOT EXISTS FOR (e:__Entity__) ON EACH [e.id]")
Graph Retriever
The Graph Retriever is constructed over a number of steps. Here’s the explanation and code for each.
The first thing to do is extract the entities present in the users question. Since a graph operates by mapping nodes to each other over edges, it is a common strategy to search by expected entities. A users question may have multiple entities mentioned which can be extracted like so. NOTE: We return a runnable chain so we can link this step together with the others later.
def create_entity_extract_chain(self):
"""
Creates a chain which will extract entities from the question posed by the user.
This allows us to search the graph for nodes which correspond to entities more efficiently
Returns:
Runnable: Runnable chain which uses the LLM to extract entities from the users question
"""
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are extracting objects, person, organization, " +
"or business entities from the text.",
),
(
"human",
"Use the given format to extract information from the following "
"input: {question}",
),
]
)
entity_extract_chain = prompt | self.llm.with_structured_output(Entities)
return entity_extract_chain
Next I construct the structured data retriever, which will generate a graph query to extract the related nodes and relationships for the entities we extracted above.
def generate_full_text_query(self, input_query: str) -> str:
"""
Generate a full-text search query for a given input string.
This function constructs a query string suitable for a full-text search.
It processes the input string by splitting it into words and appending a
similarity threshold (~2 changed characters) to each word, then combines
them using the AND operator. Useful for mapping entities from user questions
to database values, and allows for some misspellings.
Args:
input_query (str): The extracted entity name pulled from the users question
Returns:
str: _description_
"""
full_text_query = ""
# split out words and remove any special characters reserved for cipher query
words = [el for el in remove_lucene_chars(input_query).split() if el]
for word in words[:-1]:
full_text_query += f" {word}~2 AND"
full_text_query += f" {words[-1]}~2"
return full_text_query.strip()
def structured_retriever(self, question: str) -> str:
"""
Creates a retriever which will use entities extracted from the users query to
request context from the Graph and return the neighboring nodes and edges related
to that query.
Args:
question (str): The question posed by the user for this graph RAG
Returns:
str: The fully formed Graph Query which will retrieve the
context relevant to the users question
"""
entity_extract_chain = self.create_entity_extract_chain()
result = ""
entities = entity_extract_chain.invoke({"question": question})
for entity in entities.names:
response = self.graph.query(
"""CALL db.index.fulltext.queryNodes('entity', $query, {limit:2})
YIELD node,score
CALL {
WITH node
MATCH (node)-[r]->(neighbor)
RETURN node.id + ' - ' + type(r) + ' -> ' + neighbor.id AS output
UNION ALL
WITH node
MATCH (node)<-[r]-(neighbor)
RETURN neighbor.id + ' - ' + type(r) + ' -> ' + node.id AS output
}
RETURN output LIMIT 50
""",
{"query": self.generate_full_text_query(entity)},
)
result += "\n".join([el['output'] for el in response])
return result
All that is happening here is that the entities identified are merged with a graph query so we can return the related neighbours & relationships to those entities. This yields a very precise corpus of data on which to answer the users query.
Next I’ll create the unstructured part of the hybrid retriever. Remember above where we included the source documents in the graph? Now we can leverage that to create a vector index directly from the graph.
def create_vector_index(self) -> Neo4jVector:
"""
Uses the existing graph to create a vector index. This vector representation
is based off the properties specified. Using OpenAIEmbeddings since we are using
GPT-4o as the model.
Returns:
Neo4jVector: The vector representation of the graph nodes specified in the configuration
"""
vector_index = Neo4jVector.from_existing_graph(
OpenAIEmbeddings(),
search_type="hybrid",
node_label="Document",
text_node_properties=["text"],
embedding_node_property="embedding"
)
return vector_index
The last step is to bring the two methods of retrieval together and construct the combined query that we will send to the LLM. The combined query will include the hybrid retriever context & the original question from the user.
def retriever(self, question: str) -> str:
"""
The graph RAG retriever which combines both structured and unstructured methods of retrieval
into a single retriever based off the users question.
Args:
question (str): The question posed by the user for this graph RAG
Returns:
str: The retrieved data from the graph in both forms
"""
print(f"Search query: {question}")
vector_index = self.create_vector_index()
unstructured_data = [el.page_content for el in vector_index.similarity_search(question)]
structured_data = self.structured_retriever(question)
final_data = f"""Structured data:
{structured_data}
Unstructured data:
{"#Document ". join(unstructured_data)}
"""
return final_data
def create_search_query(self, chat_history: List, question: str) -> str:
"""
Combines chat history along with the current question into a prompt that
can be executed by the LLM to answer the new question with history.
Args:
chat_history (List): List of messages captured during this conversation
question (str): The question posed by the user for this graph RAG
Returns:
str: The formatted prompt that can be sent to the LLM with question & chat history
"""
search_query = ChatPromptTemplate.from_messages([
(
"system",
"""Given the following conversation and a follow up question, rephrase the follow
up question to be a standalone question, in its original language.
Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:"""
)
])
formatted_query = search_query.format(
chat_history=chat_history, question=question)
return formatted_query
In terms of building a hybrid GraphRAG implementation, there you have it. To take it up one more notch, we should really add an interface that can interact with the graph in a conversational manner.
Build a UI
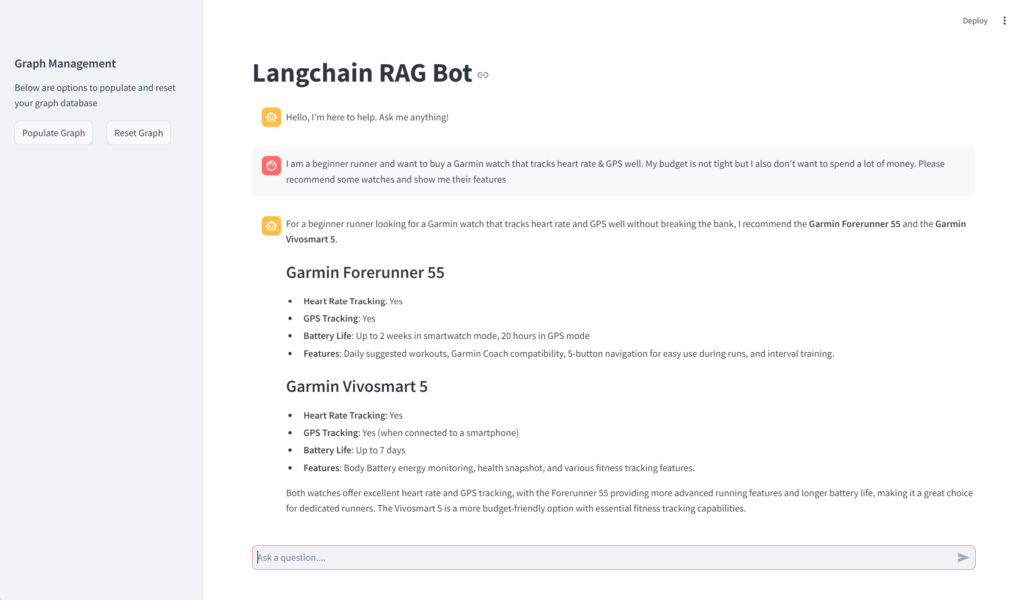
Since Streamlit makes it so easy to build up a prototype quickly, let’s go ahead and do that. The UI is broken into two sections:
- Sidebar – contains controls to manage the graph – for now this will read from pre-populated URLs contained within the code
- Main Window – This is the main chat interface – users can pose questions which will combine the models latent knowledge with specific graph based knowledge which has been provided by you
def graph_content(progress_bar, status_text):
"""
Entry point to generate a new graph. Will add controls to the UI
to perform these actions in the future
"""
print("Building graph from content")
graph_builder = GraphBuilder()
urls = [
"https://www.youtube.com/watch?v=2qHUIrdHKyg",
"https://www.youtube.com/watch?v=sAz9WQOkKb0",
"https://www.youtube.com/watch?v=o5Y95C-4kfo"
]
status_text.text("Starting YouTube Content")
progress_bar.progress(1/3)
graph_builder.extract_youtube_transcripts(urls)
status_text.text("Complete YouTube Content, starting Wikipedia Content")
progress_bar.progress(2/3)
graph_builder.extract_wikipedia_content("Garmin_Forerunner")
graph_builder.extract_wikipedia_content("Garmin_Fenix")
status_text.text("Complete Wikipedia Content")
progress_bar.progress(3/3)
graph_builder.index_graph()
def reset_graph():
"""
Will reset the graph by deleting all relationships and nodes
"""
graph_builder = GraphBuilder()
graph_builder.reset_graph()
def get_response(question: str) -> str:
"""
For the given question will formulate a search query and use a custom GraphRAG retriever
to fetch related content from the knowledge graph.
Args:
question (str): The question posed by the user for this graph RAG
Returns:
str: The results of the invoked graph based question
"""
rag = GraphRAG()
search_query = rag.create_search_query(st.session_state.chat_history, question)
template = """Answer the question based only on the following context:
{context}
Question: {question}
Use natural language and be concise.
Answer:"""
prompt = ChatPromptTemplate.from_template(template)
chain = (
RunnableParallel(
{
"context": lambda x: rag.retriever(search_query),
"question": RunnablePassthrough(),
}
)
| prompt
| llm
| StrOutputParser()
)
# Using invoke method to get response
return chain.invoke({"chat_history": st.session_state.chat_history, "question": question})
def init_ui():
"""
Primary entry point for the app. Creates the chat interface that interacts with the LLM.
"""
st.set_page_config(page_title="Langchain RAG Bot", layout="wide")
st.title("Langchain RAG Bot")
# Initialise session state
if "chat_history" not in st.session_state:
st.session_state.chat_history = [
AIMessage(content="Hello, I'm here to help. Ask me anything!")
]
user_query = st.chat_input("Ask a question....")
if user_query is not None and user_query != "":
response = get_response(user_query)
# Add the current chat to the chat history
st.session_state.chat_history.append(HumanMessage(content=user_query))
st.session_state.chat_history.append(AIMessage(content=response))
# Print the chat history
for message in st.session_state.chat_history:
if isinstance(message, HumanMessage):
with st.chat_message("Human"):
st.write(message.content)
if isinstance(message, AIMessage):
with st.chat_message("AI"):
st.write(message.content)
with st.sidebar:
st.header("Graph Management")
st.write("Below are options to populate and reset your graph database")
# Create two columns for the buttons
col1, col2 = st.columns(2)
with col1:
if st.button("Populate Graph"):
progress_bar = st.progress(0)
status_text = st.empty()
graph_content(progress_bar, status_text)
with col2:
if st.button("Reset Graph"):
reset_graph()
if __name__ == "__main__":
init_ui()
Conclusion
Let’s recap: the primary issue we face is that data is often not linearly related and can contain valuable information beyond a single “hop.” Addressing this “multi-hop” problem is where knowledge graphs become essential. They provide a more realistic representation of how information is interconnected, allowing us to query this complexity with relative ease. Constructing these graphs manually can be challenging, but with the advent of LLMs, we now have the capability to automate this process efficiently.
By developing a hybrid retriever, we can effectively match and understand the entities relevant to a user’s query. This enables us to extract the pertinent nodes and edges, resulting in a richer, more informed response that captures knowledge often overlooked by basic RAG implementations.
And there you have it, as always, the full code is available on Github. See you next time.
Support Me
I hope you liked this article, if you did and would like to support more like this I’d appreciate your help.
I run a twice weekly newsletter which delivers a balance between technical articles, quick tips for AI use & the latest news consolidated into one quick read.
Or if you’re feeling like I really deserve it – I could always use a coffee!!